A 928-question evaluation of how frontier AI agents perform on the work finance professionals actually do.
Background
Customers ask us all the time which AI model they should use. The question assumes there is a singular and objectively correct answer waiting to be found.
Finance rarely works that way. A math problem has a correct solution. A coding task has a passing test. The work inside banks, PE firms, research shops, and asset managers is different: there is often a correct answer, but arriving at it requires layers of context, interpretation, and judgment.
That nuance manifests along two dimensions. The first is contextual. A margin profile can look compelling while cash conversion deteriorates beneath it. The same EBITDA multiple that serves as a reasonable benchmark in one industry can collapse entirely in another. Leverage that looks reckless in one business can be entirely rational in another. The second is role-specific. A credit underwriter and an M&A banker optimize for different risks. A system that performs well for equity research can fail a PE associate building an LBO. The same question, asked across two desks, may require entirely different derivations depending on the workflow and objective.
Prior finance benchmarks haven't meaningfully engaged with this. FinanceBench grades short-answer extraction against fixed passages. FinQA, FinanceMath, and DocFinQA grade arithmetic against single contexts. BFB is not a harder version of those benchmarks. It's a different category: workflow-grounded, agent-executed, derivation-graded.
That does not mean there is no right answer. It means correctness in finance is often highly nuanced, and measuring that nuance matters. We've spent significant resources trying to build a framework that captures that rigor in a way that is academically credible and practically useful for the industry.
Here's what we found.
What's in the benchmark
The 928 questions in BFB span the workflows run across our customer base:
Vertical-specific skills (374): The judgment that distinguishes desks from one another: capital structure and returns, M&A and special situations, valuation, private capital, governance, and capital markets.
Metrics (301): Identifying, collecting, and computing the KPIs that drive a thesis.
Earnings and financial-statement analysis (137): Reading filings the way a financial professional reads them, and understanding what story the numbers tell.
Scenarios and model forecasting (116): Building base, bull, and bear cases from disclosed guidance and management commentary.
BFB was built for finance, by ex-finance professionals. The 52 practitioners who wrote the questions also wrote the rubrics, and a panel of 12 senior reviewers stress-tested every one. All questions are designed to have an objective answer, be time-constrained so the answer remains fixed over time (for example, “2Q25” rather than “last quarter”), and require difficult, multi-step reasoning that often draws on multiple sources.
The rubrics are the point. Every question carries one, averaging 17 line items, each tagged as Retrieval, Definition, or Calculation, and weighted 1 to 10. A model earns credit for finding the right filing even if it later miscalculates. It earns credit for the right definition of ARR even if it picks the wrong period. It loses credit at the specific step where it failed. Across the benchmark: 15,656 rubric criteria, 36,241 weighted points.
That structure is what separates BFB from prior finance benchmarks. The questions were written by people who do this work, and they are graded the way that work is reviewed at financial institutions.
How frontier models do
We graded ten frontier systems against BFB - six closed and four open-weight, including the strongest models from Anthropic, OpenAI, Google, Z.AI, Alibaba, Moonshot, and Google DeepMind. Each model ran each question three times in a minimal agent setup with access to SEC EDGAR, the public web, and a Python sandbox.
The headline result:
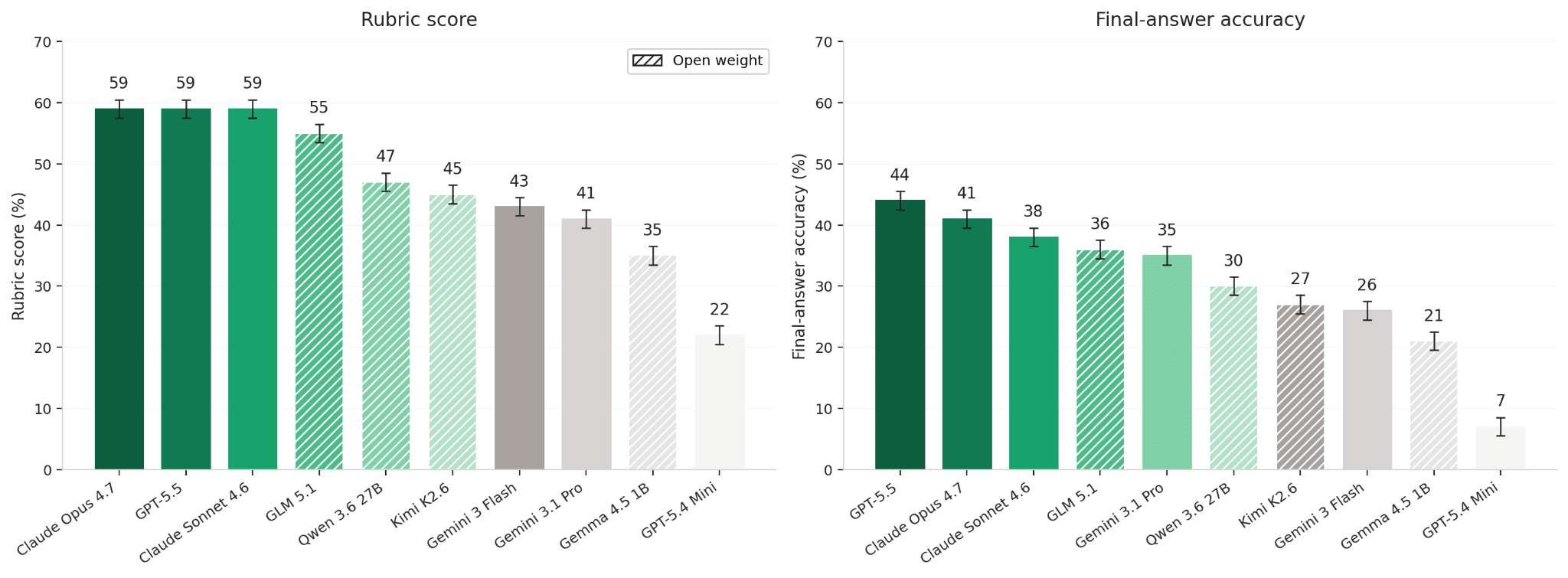
Figure 1. The 10-model leaderboard, ranked by rubric (left) and final-answer accuracy (right). The same model can move several positions between the two metrics.
Three things are worth your attention.
1. Final answers under-credit the work by 16 points
Across all evaluated models, rubric scores exceed final-answer accuracy by roughly 16 percentage points, revealing how much reasoning is invisible to binary evaluation schemes.
Models frequently retrieve the correct filings, identify the relevant accounting treatment, and follow the appropriate chain of logic, yet receive no credit because of a minor arithmetic or transcription error in the final step. A strict final-answer metric collapses these near-successes into the same category as unsupported guesses, obscuring meaningful differences in reasoning quality. Rubric grading offers a more informative measure because it captures how reliably a model can execute a complex financial workflow, not merely whether it arrived at the exact output. The distinction can materially change rankings. Gemini 3.1 Pro, for example, often produces confident answers without fully completing the underlying process, while Gemini 3 Flash reasons more methodically through the workflow and performs better under rubric grading.
2. There is no single best model
At the top of the leaderboard, Opus 4.7, GPT-5.5, and Sonnet 4.6 appear almost indistinguishable, separated by less than 0.3 percentage points overall. Read superficially, the result suggests convergence: three frontier systems reaching roughly the same level of capability.
A closer look reveals something more interesting. Across the 928 questions in the benchmark, no model among the top three leads across the dataset. Each excels in a different class of financial work. GPT-5.5 performs strongest on capital structure and M&A questions. Sonnet 4.6 leads on earnings quality and financial statement analysis. Opus 4.7 is particularly strong on private capital and forecasting tasks.
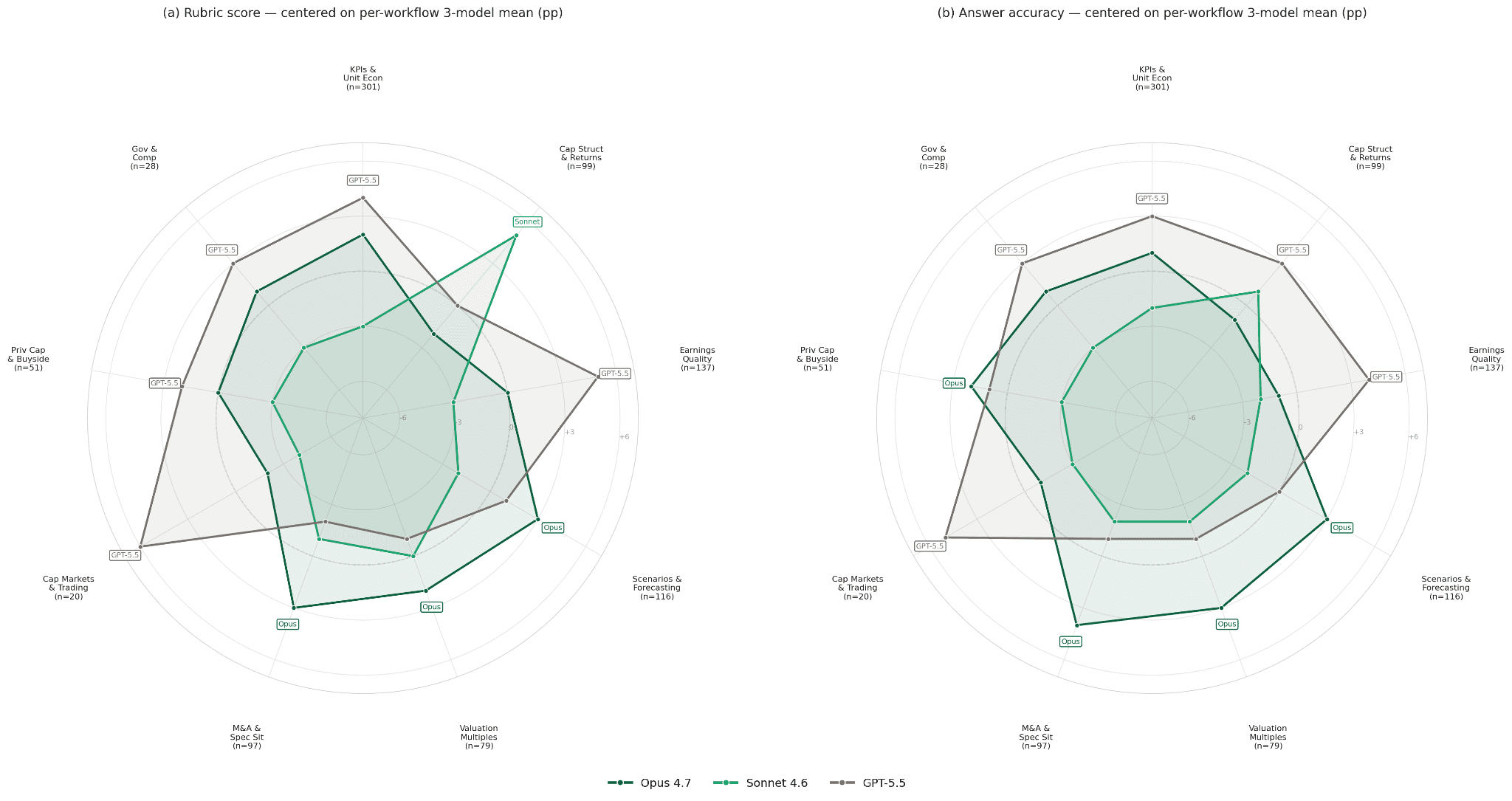
Figure 2. Per-workflow performance for the top three closed models. The polygons do not nest — each model's strength ridge sits on a different axis.
The radar plot in Figure 2 captures the pattern clearly. The polygons overlap, but they do not nest. Each model exhibits a distinct capability profile, with strengths concentrated along different workflow dimensions.
For practitioners, the implication is important. Aggregate leaderboard performance obscures meaningful variation in how models reason across financial domains. Model choice is not simply a question of selecting the system with the highest average score, but of understanding which forms of analytical work each system performs most reliably.
3. There is real headroom in routing
If different models exhibit different areas of comparative advantage, the natural next question is whether those differences can be leveraged systematically. Our results suggest they can.
We evaluated a hypothetical routing system that selects the strongest model for each question and compared it against several practical baselines:
Best single model (Opus 4.7 or GPT-5.5): 58.8% rubric
Coarse router selecting by workflow and source type: +4.5 pp rubric, +4.7 pp final answer
Best-of-ten oracle selecting the strongest response per question: +13.2 pp rubric, +13.4 pp final answer
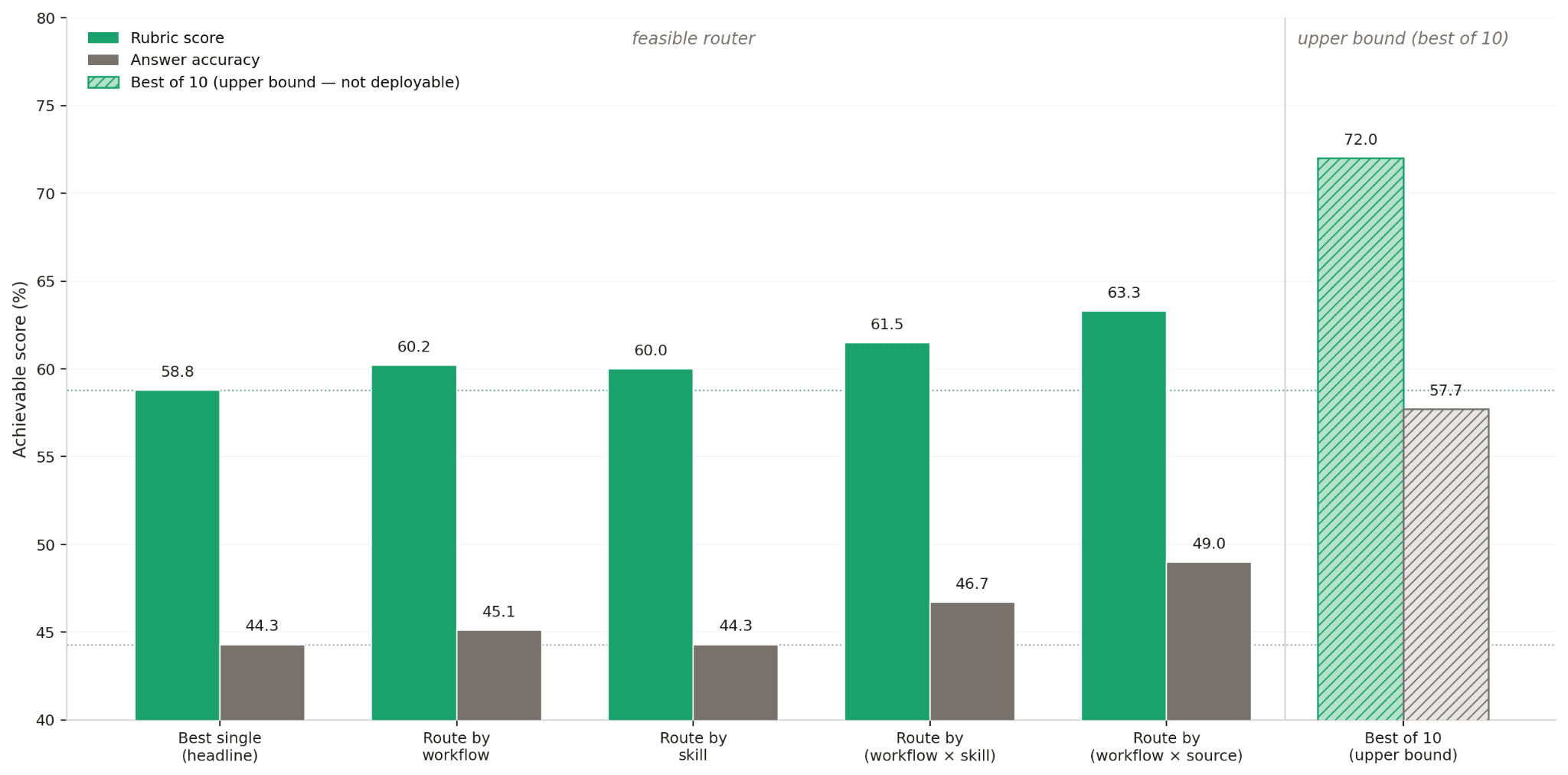
Figure 3. BFB score under increasing routing granularity. A static (workflow × source) lookup table delivers +4.5 pp; a best-of-10 oracle delivers +13.2 pp.
The magnitude of the improvement is notable. Even relatively simple routing strategies recover meaningful performance gains, while the oracle results indicate substantial remaining headroom.
The implication is that frontier model performance should not be understood solely at the level of individual systems. Increasingly, performance depends on orchestration: matching the appropriate model to the appropriate analytical task. In financial workflows, where reasoning patterns vary significantly across domains, routing is as consequential as advances in the underlying models themselves.
What we released
The paper, with full methodology and worked examples.
A 50-question stratified subset of BFB on Hugging Face, with full reference answers, rubrics, and source citations. Calibrated against the full 928-question set so that rankings on the subset closely track rankings on the full benchmark - usable for prototyping, model comparison, and reproducing our results.
The agent harness used in the paper, on GitHub.
A website, with additional findings as models get released
Why this matters for our customers
Every conversation about AI procurement in finance begins with accuracy and ends with cost. Across our customer base, improvements in model capability have been accompanied by an order-of-magnitude increase in token consumption. The naive approach is to route every task to the strongest available model and absorb the resulting cost. But at enterprise scale, that approach quickly becomes uneconomical.
The more effective approach is to treat capability and efficiency as separate optimization problems. The metric connecting the two is cost per correct answer. BFB makes that cost-efficiency frontier visible.
Once a system retrieves the correct documents and applies the appropriate financial definition, frontier models converge surprisingly tightly on the underlying arithmetic. Much of the variance in accuracy originates upstream of the model itself. Much of the variance in cost originates in the surrounding infrastructure. Buyers who treat those as a single problem end up paying frontier-model prices for workflows that a cheaper and better-orchestrated stack could handle just as well.
On our benchmark, the same task costs roughly $1.26 with Claude Opus 4.7 and closer to $0.02 through a cheaper model. This is where routing becomes strategically important. A router does not simply select the strongest model overall; it selects the most appropriate model and stack for the specific task. In BFB, even a coarse router based only on workflow and source type improves rubric performance by 4.5 percentage points over the best standalone model. A best-of-ten oracle improves performance by 13.2 points, illustrating how much capability single-model deployments leave unrealized.
As token volumes continue to rise, the economics of orchestration become increasingly important. The firms that gain the most from AI in finance are unlikely to be the ones with the largest model contracts. They will be the ones with the best routing systems: systems that continuously adapt as models improve, costs shift, and workloads evolve. That is precisely why we run BFB on a recurring cadence. The optimal deployment strategy changes every time a new model ships.
Big Finance Bench is a research initiative led by Rogo. The companion paper, methodology, and full author list will be on arXiv.
More posts


