Nov 12, 2024
Why is Internal AI Search Hard for Financial Firms?

Note: This is the first post in a series about how financial firms can prepare their internal data for AI search. It is written with a non-technical or semi-technical audience in mind. If you have any questions about the content here, feel free to shoot a note to john@rogo.ai.
Intro
A lot of firms we talk to are surprised — even disappointed — when we tell them it will take a few months of prep-work to get their internal file system ready for AI search.
We know what they're thinking: "Isn't the whole point of AI that it can figure things out on its own?" The idea seems simple enough: Take all the documents, split them into chunks, embed them in a vector database, and then when a user asks a question, find the most similar vectors and have an OpenAI model use that context to give a good answer. How hard can it be?
For half-decent answers or a quick, slick demo, not very. But for consistently reliable answers? Extremely. For a long list of reasons — ranging from the technical and interesting to the mundanely practical — this approach will not work well out-of-the-box for large document repositories. You'll need to do some serious prep-work. (What sort of prep work? Don’t worry, we'll cover that in detail later in this series.)
Reason 1: Your system probably has too many versions of each file.
Let's start with the most straightforward challenge. Whether you're an investment bank, a PE shop, or another type of financial firm, there is significant iteration on each deliverable, resulting in a ton of versions. (At least once a month I wake up in a cold sweat remembering a 2020 FinTech bake-off deck I had to version up to "v236"... We didn't win the deal.)
Having many versions of the same file is death for the "naive" embedding approach. Imagine an end user asks: "What valuation range did we show for XYZ company in their sell-side pitch last year?" But you have 85 different versions of that pitch! Worse yet, each one has a different valuation range because you were iterating on the numbers. The embeddings for those pages will look essentially identical, and we'll be relying on the inference-time synthesis model to somehow choose the version with the "vFINAL" (or the highest number).
It will get it right sometimes! Depending on the number of versions, maybe even more often than not. But "more often than not" is not the bar we're aiming to clear here. And the problem compounds exponentially when you're querying the same data point across multiple pitches.
Reason 2: Even with only final versions, there are probably redundant sources of information.
Redundant information sources are theoretically fine when they're consistent and accurate. But in practice, we almost never see that. Every firm has a vast amount of institutional knowledge (whether formal or informal, written or unwritten) about which sources are authoritative for certain pieces of information.
Imagine you're a PE associate asking: "What was our exit EBITDA multiple for XYZ deal?" Between EBITDA adjustments, post-closing adjustments, and other nuances, there are probably slightly different versions of this number across valuation reports, portfolio review docs, LP letters, and more. The AI system needs to be taught your firm's institutional knowledge so it doesn't make the same data-retrieval mistakes a summer intern would make in their first month.
Reason 3: Your end users probably want to ask questions across dimensions like date, company, and sector.
A common, seemingly straightforward search query we see from financial firms is something like: "Find a football field page we did for a SaaS company this year."
Unfortunately, this is far more complex than it appears. While the AI might infer sectors from the content it locates, how does it determine when that content was created?
If every file has its date in the name, or always has the date on the cover page of the file, we're in relatively good shape. The AI can theoretically use that information at inference time. Better yet, during indexing, we can tag documents with their dates to enable efficient filtering. But that's a big "if." Most files in your system likely don't follow such consistent dating conventions.
You might consider using the "CreatedAt" field from your drive. But in our experience, these timestamps often become unreliable through cloud migrations and system changes. Sometimes they correlate with fiscal periods rather than actual content creation dates. And even if we could reliably extract relevant dates, we still face similar challenges with countless other filtering dimensions.
The upshot? Even if embeddings worked flawlessly (which they don't... more on this below), we would need to implement comprehensive metadata tagging before indexing.
Reason 4 (…or maybe 3.5?): Embeddings aren’t naturally good for exhaustive questions.
Consider another seemingly simple query: "Find our average MOIC across all of our enterprise IT deals." To answer this accurately, the AI system needs to identify not just most of the enterprise IT deals, but every single one of them.
At scale, a naive embedding approach has virtually no chance of answering this correctly. The source-retrieval step will surface numerous chunks mentioning MOIC values. Determining which ones specifically relate to enterprise IT deals becomes extremely challenging based on embeddings alone. Add to this the complexity of multiple references to the same deal across different documents, and the problem compounds. Even if embedding search captures all MOIC mentions, expecting the inference step to filter out duplicates and correctly identify enterprise IT deals is unrealistic.
Reason 5: Different file types require different pre-processing approaches.
The naive embedding approach we described earlier attempted to be universal across all file types. Unfortunately, that's far from optimal. At minimum, you'll probably want different models for Excel files versus PowerPoints versus Word documents. Excel spreadsheets and PowerPoint presentations typically require sophisticated vision models, while Word documents might be better served by pure text models.
Making these distinctions based on file type is a reasonable starting point, but it's still probably not optimal. Each file type may require its own unique preprocessing pipeline and specialized handling.
Reason 6: Embeddings aren’t silver bullets.
This is perhaps the most critical realization when indexing internal files for AI search: Despite the hype, embeddings have significant limitations.
Off-the-shelf embedding models excel at general tasks because they're trained on massive datasets of everyday content. They can do things like understand that "puppy" is to "dog" as "kitten" is to "cat." But unless you're in the pet care roll-up space, this isn't particularly useful. For domain-specific semantic tasks, performance degrades a lot. As a practical example, standard OpenAI embeddings won't recognize "sales" and "revenue" as being as semantically similar as financial professionals would want/expect.
The obvious solution is developing a domain-specific embedding model trained on financial language & content. It's a good start. And most providers (including us) take this approach. But it's not a complete solution for two key reasons.
First, selecting the optimal model(s) isn't always obvious upfront and typically requires extensive testing and sophisticated evaluation frameworks.
Second, even with a best-in-class domain-specific embedding model, still you'll frequently be puzzled by how poorly the embeddings capture semantic meaning. The reason is fundamentally simple: Embeddings are inherently low-dimensional representations of data. This dimension reduction inevitably loses information. Semantic meaning often gets lost in this compression process.
Improving these embeddings is an ongoing area of research. We expect these models will get much better in coming years, both off-the-shelf and custom fine-tuned ones. But for now, there remains a huge amount of engineering complexity to using these embeddings effectively:
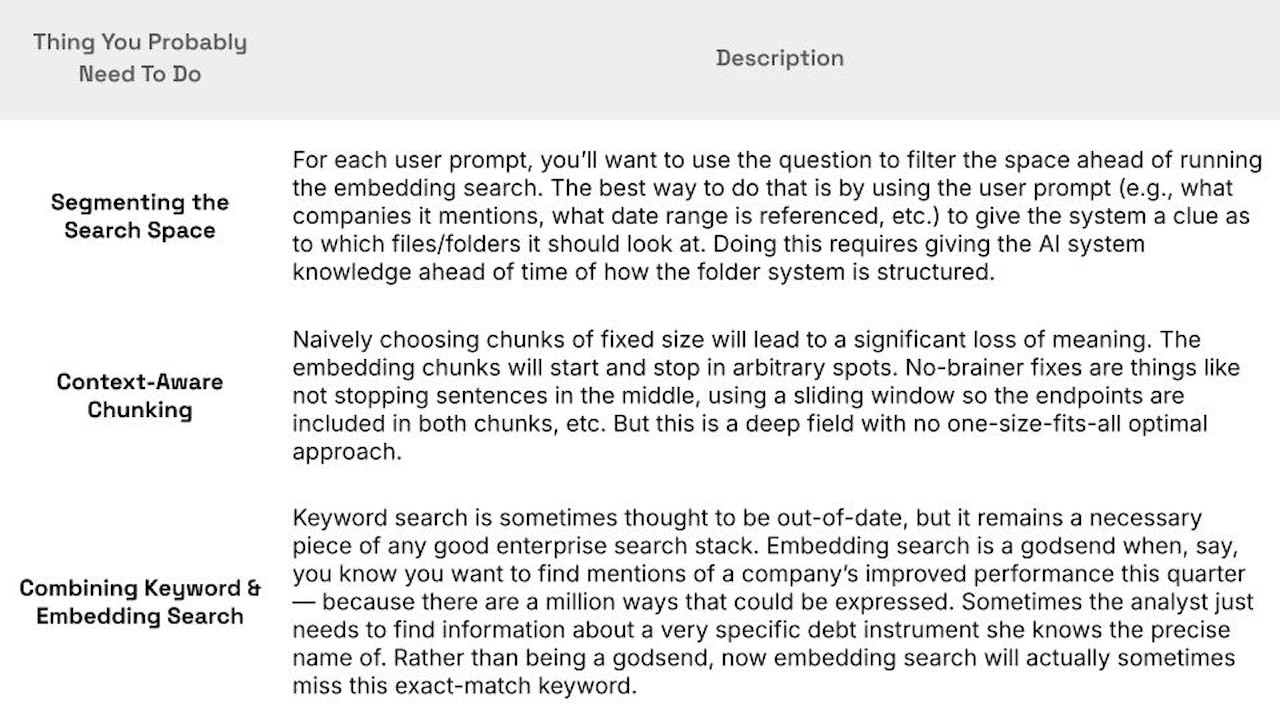
Wrap-up
The takeaway here is clear: If you're a financial firm, simply taking 100 million files, embedding them in a vector database, and asking OpenAI's latest model to answer your questions... well, unfortunately that won't work very well. You'll need to do substantial prep-work and apply sophisticated engineering techniques. There will likely be significant experimentation along the way.
While this may sound daunting, fear not: This is just the first piece in a series about how financial firms can prepare their internal data for AI search. The articles that follow are about solutions, not problems. Despite the challenges of embedding search for large file repositories, there are numerous innovative techniques for extracting high-quality answers from your internal search system — both to derive immediate value with current models and to position yourself to leverage exponential model improvements in the long term.
More articles

Welcoming Our New Head of Applied AI: Joseph Kim
Article
·
13/02/2025
We’re thrilled to announce that Joseph Kim, one of the world’s leading experts in AI and search, has joined us as our Head of Applied AI. He joins us from Google Search.

Meet the Rogo team: Aidan Donohue, AI Engineer
Article
·
28/01/2025
Meet the Rogo team: Aidan Donohue, AI Engineer

Rogo and Crunchbase Partner to Supercharge Rogo’s AI Analyst
Article
·
16/01/2025
Rogo has announced a partnership with Crunchbase, a leading provider for private company intelligence, to support the development of Rogo’s financial generative AI platform.