Sep 3, 2024
Challenges 2024-2025

At Rogo, we're tackling some of the most challenging problems in AI and finance to revolutionize how financial professionals work. Here a list of short, concrete, and hard problems we’re looking to solve in the next year:
Learning by Analogy:
We believe AI should adapt to us, not the other way around. Our goal is to create systems that can:
Learn from existing work (decks, memos, models) and apply that knowledge to new topics.
Emulate a banker's workflow by starting with existing work and making intelligent adjustments.
Handle diverse input types while maintaining intuition, domain knowledge, and interpretability.
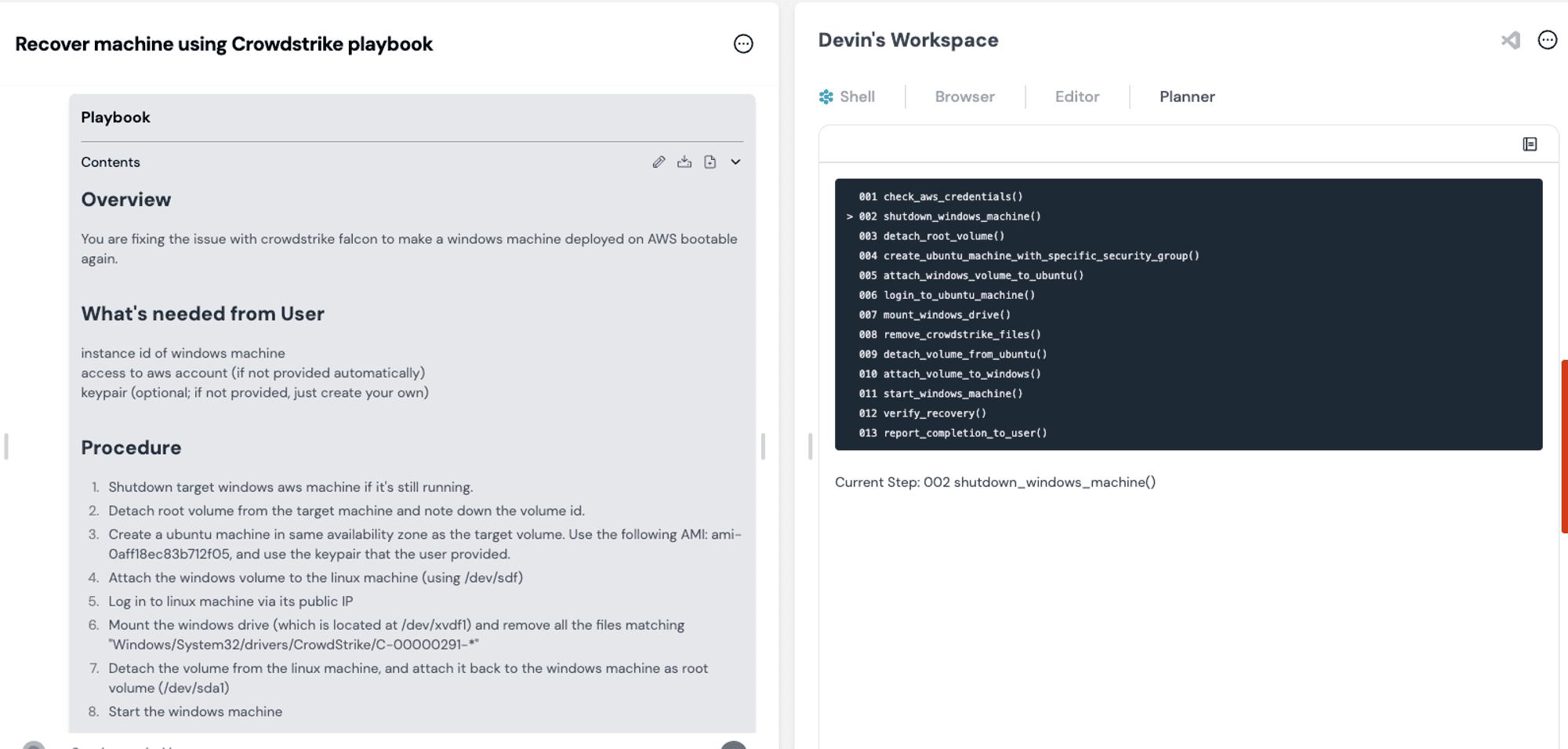
Compiled Devin steps from our friends at Cognition Labs
What makes this problem hairy is the variance in user input. Structured outputs are tractable. When writing emails, base frontier models do a good job, provided they're given an email as an example. When you're given multiple different types of documents and asked to recreate the bundle on a new subject, the problem suddenly requires intuition, domain knowledge, and interpretability that those models lack.
Promising Approaches:
Developing quickly configurable, specialized embeddings and reranking systems.
Creating "compilers" for financial documents, similar to programming language compilers.
Researching when and how LLMs should delve deeper or change course on financial topics.
Exploring financial-specific LoRA adapters, especially in conjunction with long-context models.
Exact Context:
At Rogo, we've built an expansive search engine over most financial documents, ingesting news, web articles, company filings, and structured market data every minute. Finding exactly what's relevant, quickly, is paramount at scale.
Atop this mountain of data we've built a knowledge graph that supports efficient retrieval, and we need to figure out how to scale it to quickly answer any question people have about finance.
Robustness at scale truly is the problem here — our users are just as interested in the unit economics of pool cleaning companies as they are in the peak sales of Phase 1 oncology targets. We believe that models will eventually support retrieval, but until then, we’re in the business of building tools that agents can invoke to give precise answers.
We are incredibly excited about the future of retrieval. There are so many paths the technology can and will take, beyond embeddings, keyword search, and graph lookups. Trading indexing cost in exchange for query-time speed and accuracy, what's the most efficient way to search?

To answer this, I’d have to:
Find Pfizer's Phase 1 oncology drugs and understand what they do.
Understand what is missing from their R&D pipeline compared to their peers.
Understand how much cash and debt Pfizer can raise to acquire those companies, and how much each potential acquisition has raised.
Synthesize all of the above information to provide a direct answer.
Unlike many traditional search engines, our users tend to ask complicated, vague, multi-hop questions. Simple RAG and search architectures only work for single question retrievals, so we have to think from first principles and design promising systems that will perform at scale.
Promising Ideas:
Leveraging social graphs from platforms like Microsoft Teams to improve search relevance.
Developing custom, interpretable reranking for financial document search.
Training encoders optimized for knowledge graph navigation.
Implementing agential reasoning with tool-calling capabilities.
Pushing the boundaries of context length and financial market analysis accuracy.
Instant PowerPoint Edits:
Bankers want to focus on finishing their work as fast as possible. Ideally, they should be able to automatically generate a slide deck, then iterate on it by chatting with the file to make edits and pull in fresh, relevant financial information. Just by chatting with Rogo, it should be possible to do anything you do in Excel, PowerPoint, and Word, all while having instant access to the world's most powerful financial search engine.
We don't think PowerPoint plugins are the UX to do this. Instead, we're building a way for bankers to never have to open up PowerPoint unless they want to.
An early prototype
Creating an AI system with the same intuition as a banker for PowerPoint is a tall order. But, we have a good intermediate representation that we’re quite happy with, which helps us encode intent.
Early experiments with frontier models in Rogo has led us to the following roadblocks:
Models are lazy and often will give up instead of writing significant changes.
Only writing diffs leads to significantly worse performance.
To compensate, we currently have to rewrite the entire intermediate representation of a slide with each edit, resulting in potentially thousands of tokens with every iteration of a file. This comes with the benefit of thinking with more tokens, as the model has more forward passes to sample correctly. Forcing us to only focus on diffs means we have fewer time to think.
This solution demands a hyper-fast inference infrastructure— at thousands of tokens per second — along with some incredibly intuitive and clever user design.
How might you trade off a more expensive, intelligent edit and maintain very fast inference? We might need to run the model in a background session, with some clever stream handling and UX along the way.
Promising Ideas:
Given 15 minutes of events from a Rogo PowerPoint editing session, how might you predict the next minute?
Speculative decoding for rebuilding a file from diffs, akin to our peers in code generation.
Using Anthropic’s Artifact paradigm to display progress to the user.
Working with RLHF providers to guide models to intuit what bankers mean in their requests.
Understanding the relational aspect of Excel and PowerPoint more deeply — there’s so much metadata in each that can be extracted to understand intent.
Interpretable AI through Sentence-Level Grounding
Citations are highly optimized and weighted tokens to be sampled based on how the model is trained to construct them. But they're not quite "citations," as we don't know exactly which tokens were used to generate a specific claim. The answer to which sentences affected the generation of a claim ahead of them lies within the attention layers.

Promising ideas:
Using sparse auto-encoders to identify which features significantly impacted generation.
Understanding the extent answers are sycophantic instead of truthful.
Build an intuitive UX around understanding the extent one source impacted the generation compared to another. This allows us to highlight bias in our AI models to certain types of sources, responses, and prompts.
—————
If you read this far, and you're interested in the problems we are interested in, then please consider joining us! The Rogo team is small and talent-dense, and there are a number of reasons why we think you would love to join us:
People love using Rogo. We are a rare vertical GenAI company with real usage, power users, and true ROI.
AI for Finance is a huge market. Generative AI is replacing human work, and financial professionals get paid more than anyone on earth. The commercial opportunity is a no-brainer.
You will work with very smart people. Everyone at Rogo is deeply passionate and incredibly smart.
We work hard because it's fun. Every day brings a new challenge, a new piece of feedback, and a new idea. We work very hard and are having so much fun on the journey to bring our vision to life.
Send an email to careers@rogodata.com, apply here, or send a direct message to one of our founders.

Tumas Rackaitis
CTO, Co-Founder
More articles

Meet the Rogo team: Curt Janssen
Article
·
13/03/2025
Meet the Rogo team: Curt Janssen, AI Engineer

Welcoming Our New Head of Applied AI: Joseph Kim
Article
·
13/02/2025
We’re thrilled to announce that Joseph Kim, one of the world’s leading experts in AI and search, has joined us as our Head of Applied AI. He joins us from Google Search.

Meet the Rogo team: Aidan Donohue, AI Engineer
Article
·
28/01/2025
Meet the Rogo team: Aidan Donohue, AI Engineer